The CERN Open Data Portal
You can explore the proton-proton data or the heavy ion data in the CERN Open Data portal. For more information about either of the collections, check the linked sections.
Downloading the Data
When you click any of the links, you will be directed to a webpage with information about the data. At the bottom of the page, under "File Indexes," you will find various "containers." These containers, which you can think of as folders, hold the actual data.
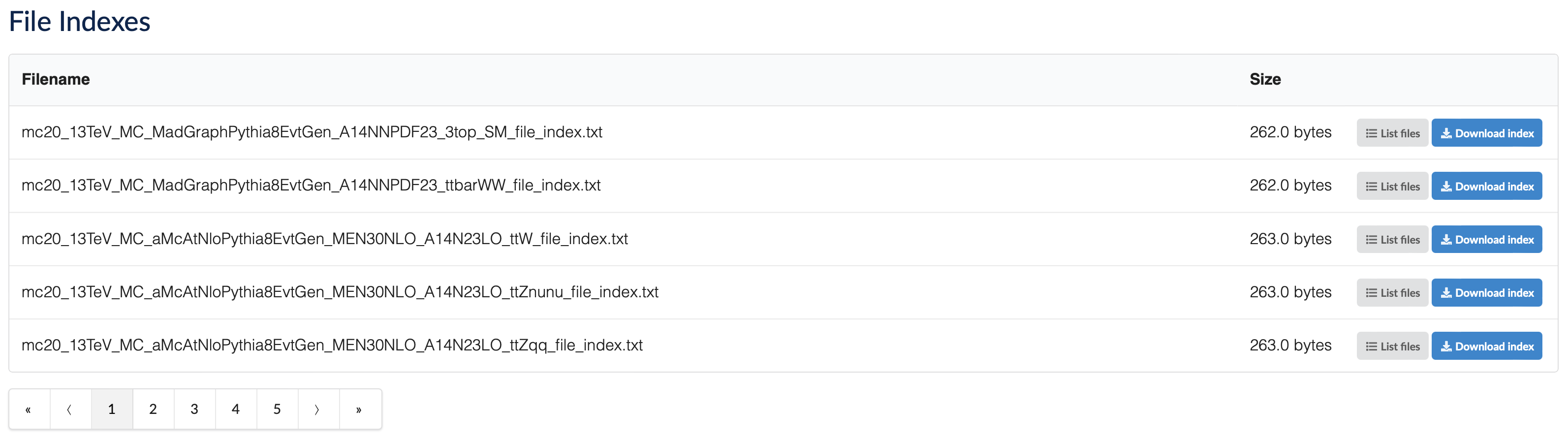
Fig.1 File indexes on the CERN Open Data Portal.
If you click on "List Files," you may find a single file or several. The data may be spread across multiple files.
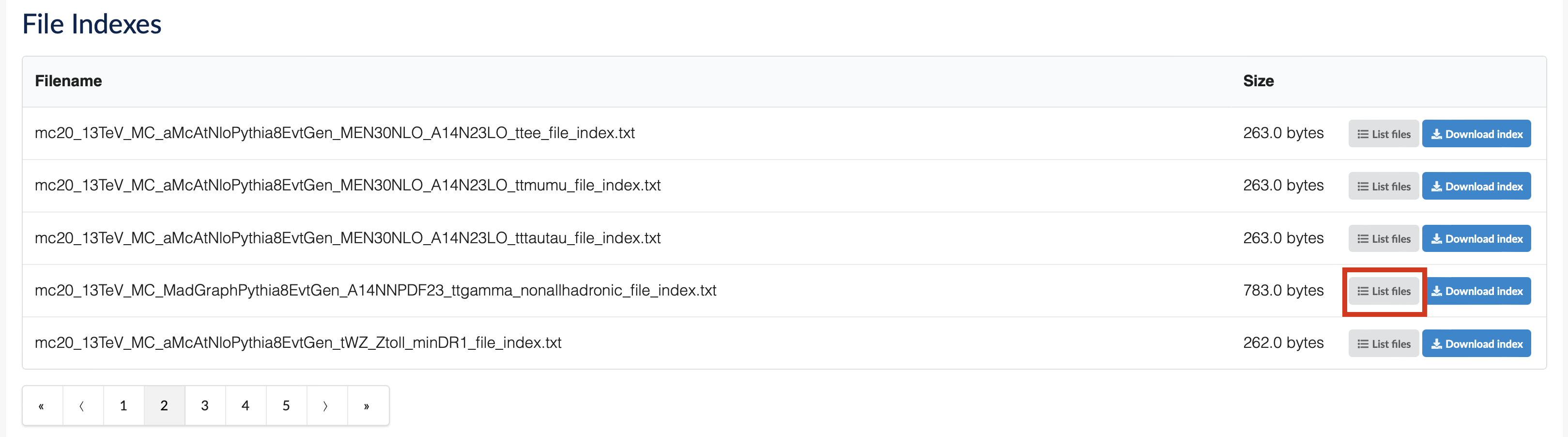
Fig.2 Clicking on "List Files" will show you the list of files associated to a container.
To download a file, simply click on the download icon next to it.
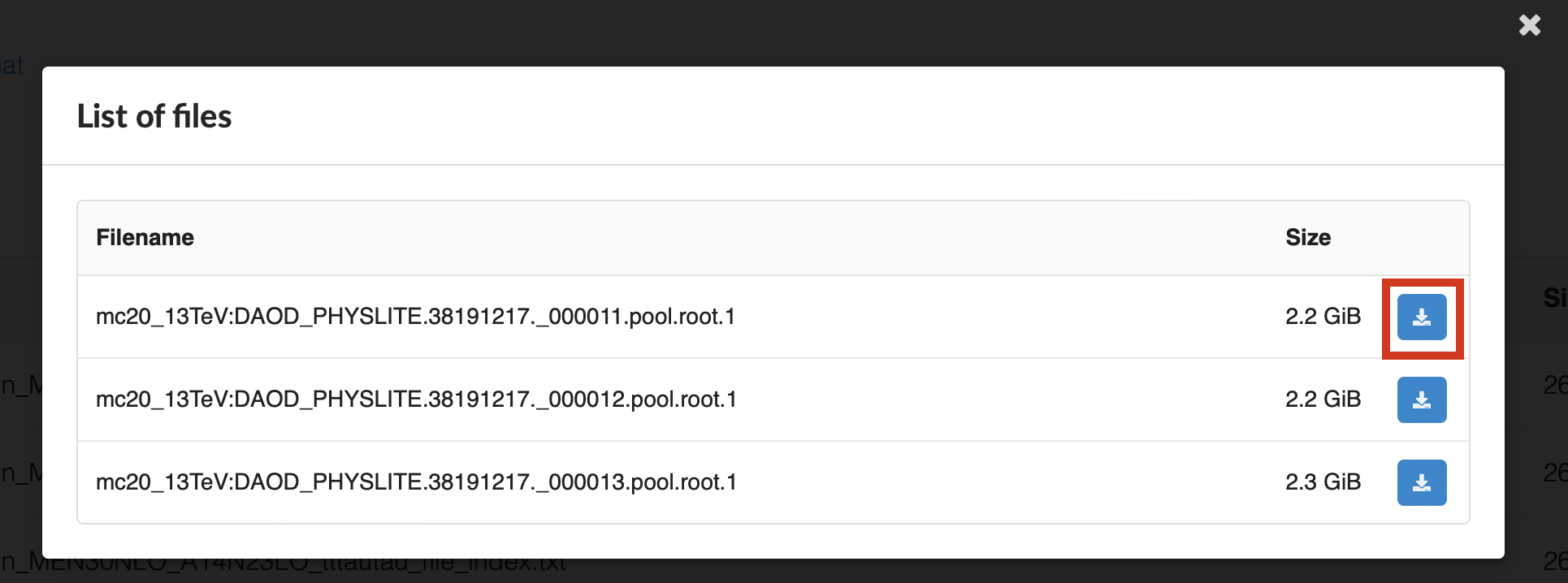
Fig.3 Clicking on the download button will start the download of the data.
Downloading data from the website can be slow, which is suitable if you only need a few samples. For downloading entire datasets, we recommend using the CERN Open Data Client.
File Naming convention
In ATLAS, we use specific nomenclature for naming files to ensure they are easily identifiable. The naming conventions vary based on the type of file (Monte Carlo simulations or detector data) to maintain clarity and organization.
Monte Carlo Simulations
The names for Monte Carlo simulations are composed by different substrings, separated by a dot:
campaign.dataset_id.short_description.production_step.data_format.processing_tags
Each part represents the following:
- campaign: Indicates the MC simulation campaign and center of mass energy, when relevant. For example, for the released data from the MC20 campaign of proton-proton collisions at 13TeV of center of mass energy is "mc20_13TeV".
- dataset_id: An 6 to 8 character numerical identifier, different for each dataset.
- short_description: Indicates the simulation tools used and the physical process described by the dataset. Common simulation tools are Powheg, Pythia, Sherpa, among others. You can check the list of simulation tools or common abbreviations for more information about you can find on this substring.
- production_step: The production step that generated the dataset. For the release data it is always "deriv" from derivation.
- data_format: The dataset format. All the released data is in PHYSLITE format, so this substring is always "DAOD_PHYSLITE".
- processing_tags: These tags indicate the configuration of the software used in each production step in the creation of the dataset. In the released MC data we have four tags: e-tag, for the event generation configuration; s-tag, for the simulation configuration; r-tag, for the reconstruction configuration; and a p-tag for physlite production. To understand more about the tags you can read about the MC production chain.
An example of a name would be:
mc20_13TeV.364350.Sherpa_224_NNPDF30NNLO_Diphoton_myy_0_50.deriv.DAOD_PHYSLITE.e7081_s3681_r13167_p6026
Which is: a Monte Carlo simulation from the mc20 project, at 13 TeV of center of mass energy. It contains the simulation of diphoton events (events where two photons are produced) using Sherpa 2.24 as event generator, particularly using the NNPDF 3.0 at next-to-next-to-leading order precision. This dataset focuses on events where the invariant mass of the photon pair lies between 0 and 50 GeV. The dataset is in PHYSLITE format, and we can identify it by its ID "364350".
The processing tags can be decoded using various ATLAS tools, but for the Open Data it is sufficient to assume that they are all consistent in their description of the data that has been released.
Decoding the short description
The short description of the physics sample, also known as the "physics short", is an attempt to pack as much information as possible about the sample into 50-60 characters. It typicaly has several parts, separated by an underscore.
By rule, the first part must be a list of the generator programs used to create the sample. These can be full names, like "Sherpa" or "Pythia8", or they can be abbreviations of names. Allowed abbreviations are: aMC for NLO aMC@NLO (aMcAtNlo when spelled out), MG for (normally LO) MadGraph, Ph for Powheg, Ag for Alpgen, EG for EvtGen, Py8 for Pythia8, H7 for Herwig7, Sh for Sherpa, PG for ParticleGun, and HepMC for samples created from HepMC text files. When Tauola or Photos are used, they are not indicated in the name.
The second part of the physics short normally describes the PDF set and/or tune of non-perturbative physics model parameters used when generating the sample. The most common tune for Open Data samples are the A14 tune and AZ and AZNLO tunes of Pythia8 and Herwig7, and the H7UE tune of Herwig7. For Sherpa samples, the tune used is the default one from the authors, and therefore the second field normally represents the version of Sherpa (e.g. 222 for 2.2.2, 2211 for 2.2.11, 2212 for 2.2.12, and so on). PDFs normally express the family and the order of the PDF, for example NNPDF30NNLO for the NNLO PDF from NNPDF 3.0, NNPDF23LO for the LO PDF from NNPDF 2.3, MSTW2008LO for the LO PDF from the 2008 release of MSTW PDFs, or CTEQ6L1 for the CTEQ6L1 PDF from the CTEQ collaboration.
Beyond that, there are no strict rules or conventions for physics short names. In some cases, the abbreviations are kept as obvious as possible (e.g. tchan for t-channel or schan for s-channel, myy for diphoton mass, or pty for photon momentum). When decays are relevant, "incl" or "inc" normally means "inclusive" (i.e. decays with the branching fractions from the Standard Model), "dil" normally means "di-lepton" (e.g. with two W bosons, both are required to decay leptonically), and nonallhad means at least one lepton (as opposed to allhad, or all hadronic).
Some samples will also include features of the production in their physics short. For example, FxFx indicates the use of the FxFx merging prescription. "HT2bias" indicates that the sample has been biased in the HT2 variable, meaning that the unweighted events have an unphysical (flattened) spectrum in HT2 in order to improve statistical precision in high energy events without the need to split the sample into multiple pieces. "SW" or "withSW" often indicates that there is biasing of the sample done with the generator itself, rather than within ATLAS software after the fact. "DS" and "DR" refer to diagram subtraction and diagram removal, two mechanisms for correcting for interference effects in single top quark production.
Often, samples are produced with a filter of some kind. Filters are normally also reflected in the physics short, usually at the end. Where possible, we try to make the meaning obvious: "MET200" means a 200 GeV MET filter, for example. One common set of filters used for the vector boson samples have to do with heavy flavor. The samples are divided into "BFilter" (events with at least one b-quark in the matrix element), "BVetoCFilter" (events with no b-quark and with at least one c-quark), and "BVetoCVeto" (events with no b-quarks or c-quarks). The three should normally be combined in order to create a complete background estimate.
It can be difficult to interpret the physics short of a sample, but with some practice most parts become readable. The job options, which are the python configuration used to generate the sample, are always the "truth" when it comes to the meaning of the individual pieces of a sample name.
Detector Data
The naming convention for detector data is similar in form, but differs in content:
project.period.data_stream.production_step.data_format.processing_tags
- project: Indicates the data taking year and the center of mass energy.
- dataset_id: An 8 character numerical identifier, different for each dataset.
- data_stream: The released datasets include two primary data streams. The first is "physics_Main," which refers to the main physics data stream used for general-purpose physics analyses. The second is "physics_HardProbes", which pertains to data derived from lead nucleus collisions.
- production_step: The production step that generated the dataset. For the release data it is always "deriv" from derivation.
- data_format: The dataset format. All the released data is in PHYSLITE format, so this substring is always "DAOD_PHYSLITE".
- processing_tags: For detector data this inncludes an r-tag and p-tag.
An example of a detector dataset name:
data16_13TeV.00298633.physics_Main.deriv.DAOD_PHYSLITE.r13286_p4910_p6026
This is a detector dataset from the data taking period of 2016. It is a dataset for general-purpose physics analyses. It is in PHYSLITE format, and we can identify it by its ID "00298633".